Debug 實錄:Auto Scaling 讓我的 Sidekiq 任務消失了
最近工作上遇到一個難題,我們的背景處理系統 Sidekiq,在 AWS Auto Scaling 自動關閉機器時,有部分的任務會憑空消失。
記錄一下追蹤問題的過程,並奉上目前的解法,希望對未來遇到此問題的人能有些幫助。
此文寫於 2021 年 10 月 24 日,解法可能因時序推移而不再適用,請自行斟酌。
系統設定
我們的服務是透過 AWS Elastic Beanstalk 部屬的 Ruby on Rails 應用程式,除了處理 HTTP 流量的 Puma 之外,還配有一支背景處理服務 Sidekiq,而使用的作業系統是 Amazon Linux 2。
Elastic Beanstalk 使用的是 Load Balancing 的模式,所以系統會自動根據負載開啟或是關閉機器。
而 Puma 及 Sidekiq 在機器上都是使用 systemd 執行的服務。
問題描述
我們有一個每隔 10 秒會執行一次的任務,每次執行的時間根據系統狀況有所不同,5 秒至 80 秒都有可能。
為了避免塞爆 Sidekiq 的任務佇列(job queue,通常是 Redis),所以我們希望的行為模式是:執行完畢後 10 秒再執行一次,用程式碼來看會是一個這樣的任務:
1 | class CleaningService |
Sidekiq 有 graceful shutdown 的設計:
- 收到「停止服務」訊號時,會暫停接受新任務,並且嘗試把正在執行的任務執行完
- 過了一段時間,會強制把未完成的任務中止,並且把這些任務重新塞回任務佇列
所以理論上來說,Sidekiq 的任務至少會被執行一次1。
以上面的 CleaningService 來說,如果 do_some_cleaning 執行到一半被中止,應該會被放回任務佇列,待 Sidekiq 重新啟動時再從頭開始執行。
但實際上這個任務常常過了幾個小時就自己消失了!
追蹤問題來源
我先自己推測幾個可能的原因會造成這個現象:
CleaningService有 bug,造成 Sidekiq 崩潰- Sidekiq 的 bug 導致任務沒有被重新被放回任務佇列
- Auto Scaling 關閉機器時,沒有讓 Sidekiq 執行 graceful shutdown
其中 1. 在經過簡單的測試以及檢視紀錄檔(log)後,可以排除。
而 2. 實際上可以透過升級成 Sidekiq Enterprise 並使用 Redis 的 SuperFetch 來保證任務執行完後才把任務從佇列中刪除2,但我猜測作者應該沒這麼壞心,故意留一個 bug 想讓大家升級到 Enterpise。此外,在手動關閉 Sidekiq 時,的確可以看到 Sidekiq 把任務重新塞回佇列。所以這個也先暫時排除。
雖然覺得很不可能,但是還是得研究 3. 會不會發生。
真的是 Auto Scaling 在搞鬼嗎?
為了瞭解 Auto Scaling 機器上的狀況,我先在機器上安插了一支 systemd 服務,會在關機前將紀錄檔打包,並且上傳到 S3。
紀錄檔裡的 Sidekiq 紀錄很不幸的,只有以下內容:
1 | ... |
原本預期應該有的「讓執行中的任務有機會完成」以及「強制把未完成的任務中止,並且把這些任務重新塞回任務佇列」都沒有被記錄到。
但可以知道的是,系統有嘗試執行正常關閉程序,但是後面發生了什麼事,不得而知。
S3 沒有紀錄,那硬碟上有嗎?
為了更進一步瞭解問題,我開始懷疑傳到 S3 上的資料有少,但因為機器在關閉之後,附掛在上面的硬碟也會一起被刪除,所以沒辦法直接看裡面的內容。
這裡可以透過 AWS 的 API,將機器的硬碟設定為「不隨機器關閉而刪除」3,這樣一來,就可以在機器關閉之後,另外開一台新的機器,並掛載舊的硬碟4,查看關機後舊硬碟上的資料。
在這之前,我還另外把寫入紀錄檔用的服務 rsyslog 設定為採用永久性儲存,避免在關機過程中,因為 rsyslog 因為過早被關閉,而遺失後續尚未關閉的服務產生的紀錄檔5。
硬碟上真的有!
在掛上舊硬碟之後,打開 Sidekiq 的紀錄檔,發現最後幾行寫著:
1 | INFO: Shutting down |
可以看到系統有嘗試讓 Sidekiq 進行 graceful shutdown,不過 Sidekiq 在當時已經沒有辦法跟 Redis 連線了。主要是因為網路層的服務比 Sidekiq 更早被關閉,所以產生此現象。
怎麼解決?
要解決這個問題最直接的方式就是修改 Sidekiq 的 systemd 服務描述檔,讓它會在網路層的服務關閉前先關閉。
但因為我們目前使用的是 AWS 的 Elastic Beanstalk,描述檔是由它自動產生的,如果要修改,可能會需要在每次有系統升級時,都確定沒有影響到其餘的功能,維護的成本偏高,所以暫時不考慮。
EC2 Auto Scaling Lifecycle Hooks
除了上述方法外,其實 AWS 的 Auto Scaling 有針對這種使用情境,設計專門的機器狀態,讓開發者在機器關閉前,進行一些必要的步驟,以確保機器可以安全地被關閉6。
在機器關閉前,Auto Scaling Group 會先讓機器進入 Terminating:Wait 的狀態,此時有至多 7,200 秒的時間執行必要的動作,動作完成後,由開發者觸發 API 讓機器進入 Terminating:Proceed 狀態,機器就會正式關閉。
完整解法架構
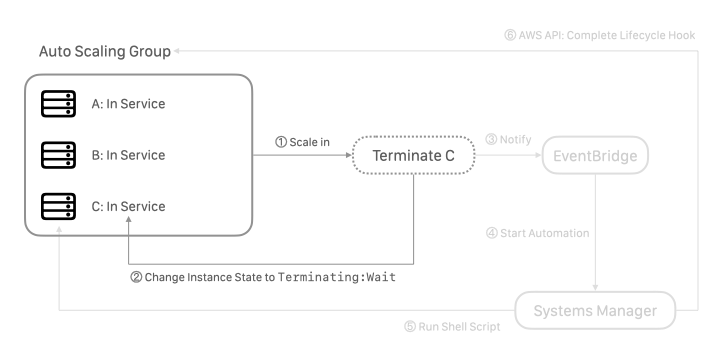
最後採用的完整的流程如下,Auto Scaling Group 根據給定規則,決定該關閉機器 (scale in),Auto Scaling Group 將欲關閉的機器設定為 Terminating:Wait 狀態。
這邊需要先在 Auto Scaling Group 中建立 Lifecycle hooks,加入 Instance Terminate 的 hook,詳細的操作方式可見官方文件。
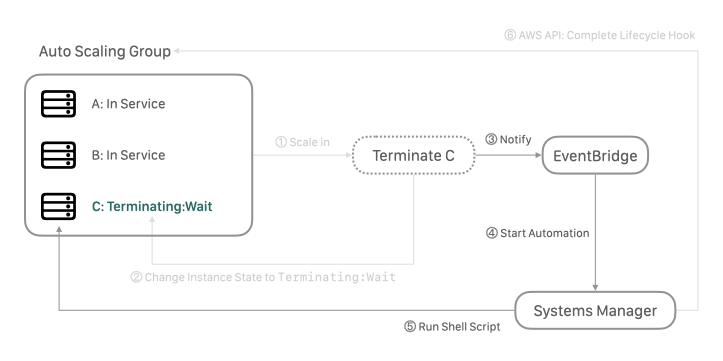
接著執行 graceful shutdown 流程。
這裡可以透過 AWS Systems Manager 搭配 AWS EventBridge 來實作。
Systems Manager 是用來管理機器的服務,其中包含:在機器上執行一段腳本、呼叫 AWS API;而 EventBridge 則是可以監聽在 AWS 服務中被觸發的事件,然後進行相關操作。
利用過 EventBridge 監聽 Terminating:Wait 事件,收到事件後,觸發在 Systems Manager 裡預先撰寫好自動化文件,即可進行 graceful shutdown 以及呼叫 API,最後完成關機步驟。
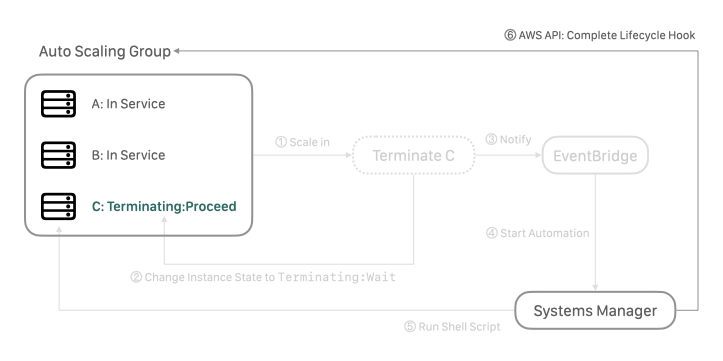
在 Systems Manager 自動化文件的最後一個步驟,觸發 AWS API 讓機器進入 Terminating:Proceed 狀態:
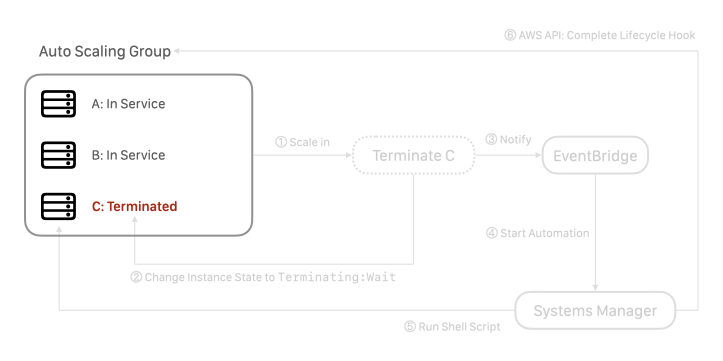
Auto Scaling Group 在收到請求後,正式將機器關閉:
詳細的 Systems Manager 自動化文件可以參考這個 Gist。
套用這個解法後,可以從紀錄檔中看到 Sidekiq 正確的被停止,並且把未完成的任務放回任務佇列,確確實實地解決這個問題。
後記
Debug 最美好的就是一切苦盡甘來的感覺,但如果可以,還是不要苦最好。感謝你讀到這裡,祝福你所有的問題,都可以從 Stack Overflow 複製貼上就解決 😌
- 1.Sidekiq wikis - Best Practices↩
- 2.r/rails - Getting Sidekiq to play nicely with auto-scaling↩
- 3.AWS docs - Preserve Amazon EBS volumes on instance termination↩
- 4.AWS docs - Make an Amazon EBS volume available for use on Linux↩
- 5.Server Fault - Wait for service to gracefully exit before machine shutdown/reboot↩
- 6.AWS docs - Amazon EC2 Auto Scaling lifecycle hooks↩